
美陸軍智能化指揮系統技術研發
軍工資源網 2022年06月30日2007年,美國DARPA開始資助推進“深綠計劃”,目標是改進美陸軍的旅級C4ISR系統,提高指揮官“觀察-判斷”(OODA前兩步)效率,更直觀展示不同決策下可能出現的戰場結果。“深綠計劃”的具體主要功能是協助指揮官創建行動指令(Courses of Action,COA),填補行動細節、開發替代方案以及評估決策對整個作戰計劃帶來的影響。
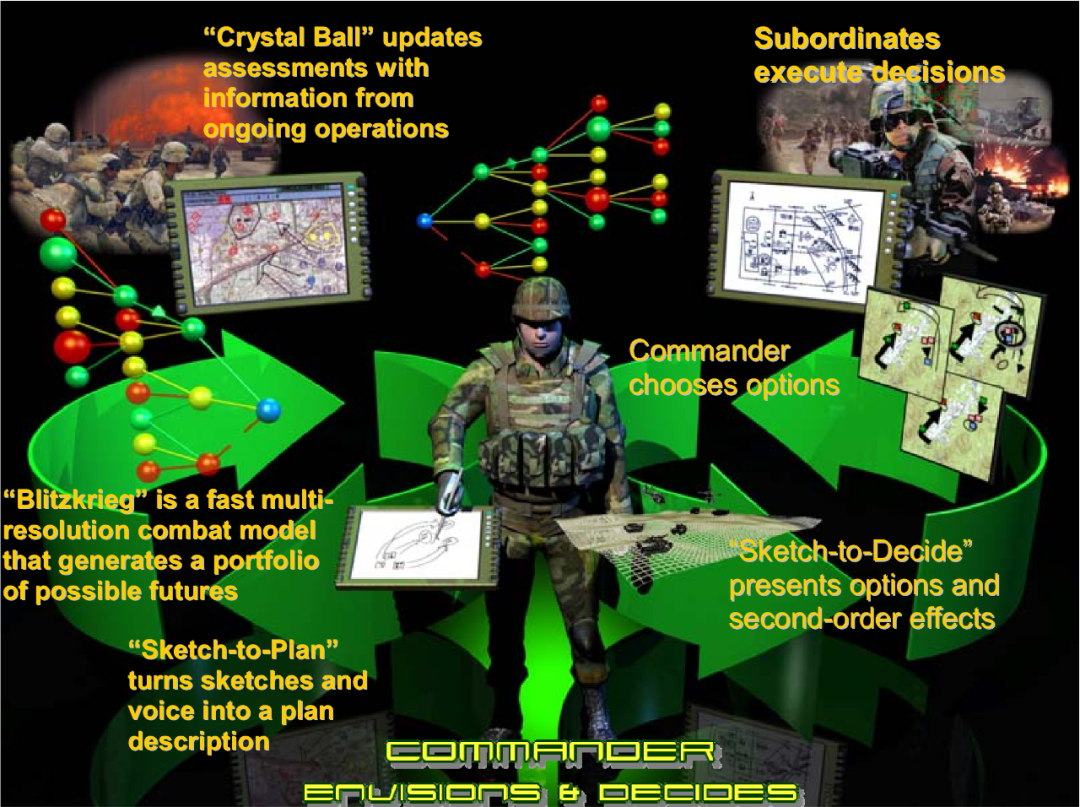
“深綠計劃”基本原理是將各部隊的“選項草圖”的排列組合在一起,有可能產生許多不同結果的戰場預測。這些可能的預測會被編制成一個“類圖表”的結構,指揮官基于此探索更多未來可能,進行“假設”作戰演練,隨即生成更多可能的戰場預測。“深綠計劃”從正在發生的戰場信息中提取有效信息,計算評估未來不同戰場發展方向的概率,裁剪掉不太可能發生的情況后,幫助指揮官更加聚焦于更大概率發生的戰場場景,確保指揮官不會面臨無從選擇的情況。
“深綠計劃”主要有三個部分組成,分別是“閃電戰”(Blitzkrieg)、“水晶球”(Crystal Ball)和“指揮官助手”(Commander’s Associate)。
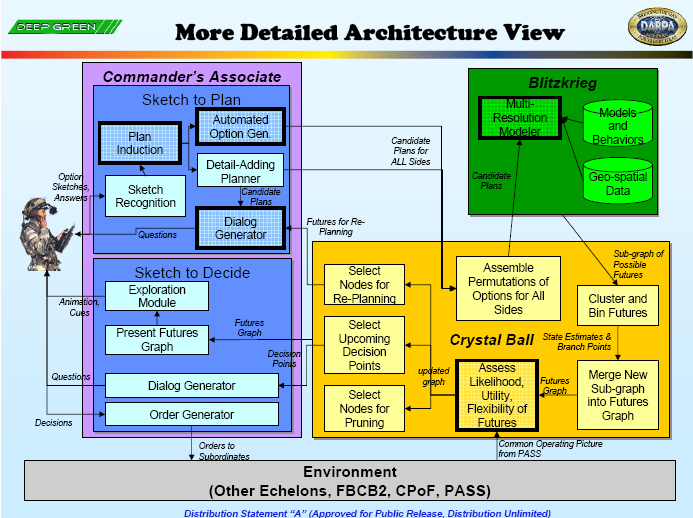
“閃電戰”部分主要用來實現的分析功能,通過自動化的分析工具對采集的戰場數據進行定量和定性的分析,生成可能出現的一系列未來結果,有些結果甚至超出人們最初的考慮范圍。隨著時間的推移,閃電戰應該學會根據所提供的選項更好地預測可能的未來。“閃電戰”可以識別各個分支點,分別預測可能產生的結果,并計算每個結果的可能性,然后繼續沿著每個路徑進行模擬。“閃電戰”具有一定的創造性思維,不僅僅是簡單輸出數百或數千次隨機模型的“蒙特卡羅”運行結果。
“水晶球”部分則是用來實現系統的總控功能,主要功能包括控制“閃電戰”的運行;根據采集的戰場信息,對戰場的實時態勢進行更新;利用采集的信息更新戰場態勢,方便指揮員在“草圖”上進行下一步規劃;向指揮員提出優先選項。
“指揮官助手”有兩個主要的子部分,“草圖到計劃”(Sketch to Plan)和“草圖到決定”(Sketch to Decide)。“草圖到計劃”為指揮官提供了快速生成定性、粗顆粒度的作戰方案(COA)草圖的能力;當指揮官繪制草圖時,計算機將觀察草圖的繪制,并監聽指示順序、時間、意圖等的關鍵詞,從草圖和關鍵詞中歸納出計劃和指揮官的意圖。“草圖到決定”是向指揮員提供未來可能的選擇和更新。
“深綠計劃”的重點是成為一個幫助指揮官快速生成決策選擇的工具(雖然指揮官通常不希望機器生成行動方案)。DARPA對“深綠計劃”的愿望是將大量計算和預測工作轉為讓人工智能機器來進行,更進一步提高效率和準確性,幫助指揮官加快戰場決策節奏,但是到2014年驗收時,實際可使用的只有“草圖到計劃”功能。“深綠計劃”所面臨的問題是計算機究竟能否理解戰場的實時態勢,決策所依據的信息是否真實、是否全面、是否可量化,最困難之處還是對敵方的決策如何假定。“閃電戰”的推演功能也存在推演偏離度過大的問題,其魯棒性值得懷疑,并且敵方的作戰決策也在不斷調整,反身性的也同樣影響到“閃電戰”的推演結果。
2016年,美陸軍通信與電子研究、開發和工程中心(CERDEC)啟動了“指揮官虛擬參謀”項目,目的是采用工作流和自動化技術幫助營級指揮官和參謀監控作戰行動、同步人員處理、支持實時行動評估。2018年,“指揮官虛擬參謀”完成了工作流程結構組建工作,并實現了任務自動化概念驗證。

“指揮官虛擬參謀”借鑒了美國蘋果公司Siri、谷歌公司Google Now等人工智能語音系統產品的思路綜合應用認知計算、人工智能和計算機自動化等智能化技術,來應對海量數據源及復雜的戰場態勢,提供主動建議、高級分析及針對個人需求和偏好量身剪裁的自然人機交互,從而為陸軍指揮官及其參謀制定戰術決策提供從規劃、準備、執行到行動回顧,全過程的決策支持。根據美陸軍CERDEC所說,“指揮官虛擬參謀”將利用自動化和認知計算技術來應對戰場上大量的數據源和高度復雜的態勢,從而作為“參謀”幫助指揮官做出更準確的決策。因此,“指揮官虛擬參謀”具有數據聚合、集成敏捷規劃、計算機輔助運行評估、基于事件的當前任務和態勢的持續預測等功能。
(1)數據聚合:通過與現有指揮系統的接口提供數據聚合,以根據需要整合和調解來自參謀計算機系統、傳感器或前線士兵的數據信息,并為指揮官提供聚合數據收集;
(2)集成敏捷規劃:支持戰爭博弈、準備、排演,及實現任務執行過程中的人機協作;
(3)計算機輔助運行評估:基于當前、未來及替代方案等,向指揮員持續提供計算機支持的在線評估;
(4)持續預測:基于態勢數據和當前計劃,識別和推理態勢的演變,生成告警,和具有一定置信度的未來態勢圖。
“指揮官虛擬參謀”運用了機器學習和用戶配置算法,系統行為可以在機器學習訓練期間或實際應用期間隨時調整。“指揮官虛擬參謀”的目標包括學習和識別用戶行為習慣,測試和更新敵人戰術模型以及本地環境。通過學習經驗豐富的指揮官的行為決策習慣,形成珍貴的數據記錄,最終可以生成供新指揮官參考使用的知識、作戰過程和作戰經驗。
“指揮官虛擬參謀”項目是美陸軍后方研究人員為指揮官提供指控支持的長期愿景的一部分,并且直接支持美陸軍2020~2040作戰概念,作為陸軍執行任務指揮、增強態勢理解、優化人員績效、協助培養未來指揮官的關鍵技術支持。可以看出,“指揮官虛擬參謀”大量借鑒了美陸軍之前的研究積累,就包括“深綠計劃”的研究成果。CERDEC將“指揮官虛擬參謀”項目打造為一個開放式架構平臺,可以與其他CERDEC或美國防部S&T平臺融合,還可以作為孵化器開發一系列有用的數字決策支持功能。
2018年5月,美陸軍訓練與條令司令部宣布,多域戰概念正式轉變為多域作戰;同年12月,美陸軍訓練與條令司令部發布《2028多域作戰中的美國陸軍》,將多域作戰概念寫入條令。多域作戰具有作戰領域多域化、作戰要素融合化、作戰編成彈性化、作戰體系去中心化等特點,因此傳統的指揮控制經典理論已經難以適應多域作戰的指揮控制。
2021年5月,美陸軍研究實驗室(Army Research Laboratory)發布了《面向多域作戰(MDO)指揮控制(C2)的人工智能(AI)》倡議文件,指出美陸軍在2035年的多域作戰行動中,需要具備敏捷、自適應的人工智能指揮控制系統,以快速同步多個作戰行動。該系統可在復雜、快節奏和極度活躍的多域作戰中提供作戰規劃和決策支持功能,能夠分析敵方的活動;通過不斷地感知、識別和快速利用新出現的優勢窗口,持續對戰役進行規劃、準備、執行與評估,從而使美陸軍的各種能力能夠快速響應。隨著近些年來基于深度增強學習(Deep Reinforcement Learning)算法的發展,在多個戰略類型游戲中已經展現出了實力,未來在多域作戰指控領域有巨大的應用潛力。
美陸軍研究實驗室還提出了一項“人工智能多域作戰指控應用”的指揮官戰略倡議(“AI for C2 of MDO” Director’s Strategic Initiative),目標是探討了基于深度增強學習算法可用于評估紅軍狀態、評估紅藍軍戰斗損失、預測紅軍的戰略和行動、基于所有情況制定藍軍計劃的能力水平。采用基于深度增強學習算法的人工智能技術,有可能為藍軍制定更具有創新性的作戰計劃,可以比經驗豐富的軍官更快的抓住潛在機會窗口。在倡議中,美陸軍研究實驗室探索性的使用深度增強學習算法在作戰行動之前制定詳細計劃,并在執行期間生成實時計劃和建議。主要目標是驗證:基于深度增強學習算法的概念化設計和實施,看是否能夠生成與軍事指揮官一致的作戰計劃(或更優化的作戰計劃);將“人”納入“命令和學習循環”,并評估這些“人在回路”(Human-in-the-loop)解決方案。
從美陸軍指揮控制系統的智能化成果上可以看出,這些指控系統主要針對的是戰術級指揮,基本還是基于OODA模型方法,重點在戰場態勢的自主研判及預測運用、情報偵察智能分析、作戰籌劃智能決策、作戰過程精確描述、敏捷響應等方面。2019年,美軍提出了“馬賽克戰”概念,融合了作戰云、多域作戰、忠誠僚機等理念,更加需要依賴高度智能化的指揮控制系統。為適應未來無人/有人協同的路戰場環境,美陸軍十分重視人工智能在指揮控制領域的應用,不僅在戰術層面,更加注重在戰略層面通過計算推演提高戰場態勢認知、判斷、決策,并且還能夠同步實現火力網的智能化指令控制。目前,美國谷歌公司旗下的DeepMind開發的“Alpha”系列人工智能產品已經具備自我博弈對抗學習、人機博弈對抗學習的能力,并且開始在美陸軍指控系統中試驗性應用。(北京藍德信息科技有限公司 研究員 米佩琛)